Someone commented, "so it's just another AI detector?"
No - Slop Check was designed for creators who already use AI, built from scratch for a different problem.
First and foremost, GPTZero is a good project. We used GPTZero and Originality.ai ourselves when we were first testing AI-generated content in our pipelines.
GPTZero proved that statistical classifiers could reliably distinguish AI text from human text. They built a real product around perplexity scoring, they scaled it, and for the use case of catching AI submissions in academic and editorial settings, it works.
However, GPTZero answers a binary question: "Did AI write this?"
As we scaled ViewDAO Studio's content generation for crypto and AI creators on X, we kept running into the same problem: posts that passed GPTZero were still getting called out as AI slop in the replies. The detector said "human." The audience said "bot."
We debated internally, on continuing to use detection tools as our quality gate, or build our own scoring system from scratch.
Two factors drove our decision:
#1 - The creator workflow is different from the editor workflow
GPTZero was built for editors, teachers, and publishers. People who receive text and need to verify whether a human wrote it. The answer they need is binary: yes or no.
Creators have a different problem. They already know they used AI. They used it on purpose. What they need is not a verdict. They need to know which specific patterns in their draft will make the audience stop trusting them. And they need that feedback before the post goes live, not after.
A probability score ("87% likely AI-generated") gives a creator nothing to work with. Which sentence? Which word? Which structural pattern? GPTZero doesn't say. You get a number and you're on your own.
#2 - Short-form content breaks perplexity scoring
GPTZero uses perplexity and burstiness. It measures how predictable the text is at the token level. Low perplexity means the model picked the statistically obvious next word at every step. High burstiness means sentence complexity varies in the way human writing does.
This works well on essays, articles, long-form text. It falls apart on a 280-character tweet. There aren't enough tokens for the classifier to be confident. GPTZero's own documentation acknowledges reduced accuracy on short-form content.
Creators post on X. Most of their content is short-form. We needed something that works at tweet length, not just essay length.
We built Slop Check to score what audiences actually react to, not what's statistically detectable at the token level.
Now the detailed differences between GPTZero and Slop Check:
Difference at the core: detection vs. craft scoring
GPTZero and Slop Check both analyze AI-generated text. Both produce scores. Both are trying to solve a quality problem. They differ on one decision: what question they're answering.
GPTZero's bet is detection. It asks "was this written by AI?" and returns a probability. You get a forensic answer. GPTZero's strengths come from committing to that surface: years of production use, academic adoption, batch scanning, a large user base, and integration with plagiarism tools like Originality.ai.
Slop Check's bet is craft. It asks, "does this read like AI to the audience that will see it, and what specifically triggers that reaction?" We think this is the right question for two specific use cases: creators who use AI on purpose and need to ship content that sounds like them, and autopilot systems that need to gate content quality without a human reviewing every draft.
Different bets, different strengths.
What the difference means in practice
Slop Check gives you the why, not just the what
When GPTZero flags a post, you get a probability. 87% likely AI. Okay. Now what? You stare at the text and guess which parts sound robotic. Maybe you rewrite the whole thing. Maybe you change a few words and paste it back in. Trial and error.
When Slop Check flags a post, you see exactly which patterns fired. The em dash on line two. The word "leverage" in the middle paragraph. The three-bullet structure at the end. Fix those three things, and the score drops from a 7 to a 3. You know what to change and why.
Five dimensions instead of one number
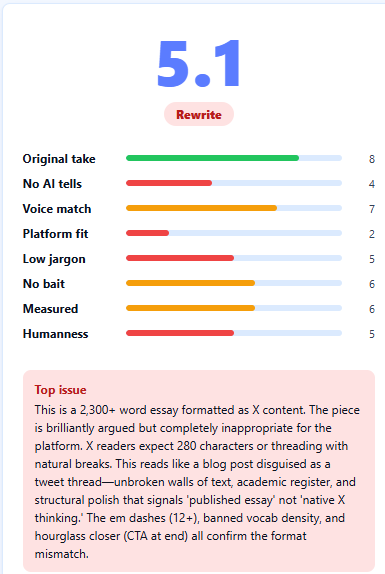
We score every post 0-10 across five dimensions:
Original Take - does the post contain a position someone could push back on? A specific claim, a named example, a real number? "AI is changing the game" scores high (bad). "Claude Haiku runs the scorer in 1.2 seconds per post" scores low (good). Specificity is the signal.
No AI Tells - the pattern-matching layer. We check for vocabulary that spikes 3-5x in AI text compared to human posts on X. Words like "delve," "pivotal," "robust," "transformative," "tapestry." An em dash is an automatic +2. These aren't style preferences. They're the words that X audiences have already learned to flag. One "utilize" in an otherwise strong post and the replies shift from engagement to "bot account."
Voice Match - does the post sound like a specific person or could it have come from any account running the same model? Recognizable cadence and vocabulary scores low. Generic scores high.
Platform Fit - three bullet points work on LinkedIn. On X, they read as ChatGPT. Engagement bait tanks this score everywhere.
No Bait - fake urgency ("This changes everything"), symmetric takes that refuse to pick a side, hollow closers ("Watch this space"). Content optimized for impressions instead of credibility.
GPTZero gives you one score. We give you five scores and the specific phrases that triggered each one.
Inline scoring vs. external checkpoint
GPTZero lives outside your workflow. You write something, copy it, paste it into GPTZero, read the result, go back to your draft, make changes, paste it again. It's an audit tool.
Slop Check runs inside ViewDAO Studio's content generation pipeline. Every draft gets scored before it hits your queue. The autopilot uses the score as a gate: anything above 6 gets held as a draft instead of posting. That threshold is configurable per creator.
1-3 publishes automatically. The post reads human.
4-6 gets held. Passable but detectable. You review it, or the generator retries with the specific flags as constraints.
7+ gets queued for full rewrite.
The scoring model is Claude Haiku. Fast enough to run on every single post. The check adds about 1-2 seconds. You don't notice it. Your audience would notice if it wasn't there.
Academic and editorial detection (GPTZero's home turf)
If you're a publisher vetting 2,000-word articles for AI generation, perplexity-based detection is the right approach. Long-form text gives the classifier enough tokens to be confident. Originality.ai adds plagiarism scanning on top. For catching AI submissions at scale in academic and editorial contexts, these tools are built for the job, and they've been doing it longer than we've existed.
Slop Check is not trying to be a forensic detector. It doesn't tell you whether a human or machine wrote the text. It tells you whether the text reads like a machine wrote it to the specific audience that will see it.
The GEO layer (something detection tools don't touch)
Slop Check has a sibling we built called the GEO (Generative Engine Optimization) scorer. Different concern, different score.
Slop scoring asks "does this sound human?" GEO scoring asks "will ChatGPT, Perplexity, or Google AI Overviews cite this when someone searches?"
Those AI search surfaces are real discovery channels now. Content that gets cited by them compounds. Every AI answer that references your post sends traffic back.
The GEO scorer looks at whether the opening sentence directly answers an implied question (AI search engines extract the first self-contained answer they find), whether the passage length sits in the 130-170 word extraction window, how many specific facts are included, and whether the content is self-describing. A post can have a perfect slop score and a terrible GEO score. We've seen this happen constantly in our beta.
GPTZero and Originality.ai don't do anything like this. They were built to detect AI. We're trying to optimize for how AI systems discover and rank content.
Pricing
GPTZero: Free tier with limited scans, then paid plans starting around $10/month. Originality.ai: Pay-per-scan model. ViewDAO Studio Slop Check: Included in ViewDAO Studio. Free for ViewFT users.
Recap:
The single difference between GPTZero and Slop Check is the question they answer - "was this AI?" vs. "does this read like AI, and what do I fix?"
But this decision leads to many differences down the line.
For our needs:
#1 - built for creators who already use AI, not editors trying to catch AI. #2 - works on short-form content where perplexity scoring falls apart.
Slop Check over binary detection is the obvious bet for our audience:
Creators already know they used AI. The binary question is irrelevant. They need to know which patterns will get them called out.
Five dimensions with traceable flags instead of one probability score. You see what to fix, not just that something is wrong.
Inline with the content pipeline. No copy-pasting into an external tool. Every draft is scored before it can post.
The GEO layer optimizes for AI search discovery on top of slop detection. Detection tools only look backward. We look forward too.
We're building ViewDAO Studio as the content platform for crypto and AI creators - but the slop problem isn't unique to our users, it's everywhere AI-generated content ships. That's why we're writing about how it works in detail - so the whole space gets better at this.
Try it at https://viewft.com/ and drop your results below. I'll answer every question.
Check out the GitHub repo here: https://github.com/Viewfin-Labs/Slop-Check